08 Feb 2025
Introduction
Following the first post about .NET Aspire and AWS, I want to explore now the possibility of using AWS resources with .NET Aspire to enable a local development environment that is quite similar to the one available in the cloud. Locally replicating a cloud environment is currently a big challenge for developers. The issue becomes very high if you want to use serverless solutions, like Lambda or DynamoDB. We will see what the current possibilities are with .NET Aspire.
Using DynamoDB Local
With AWS you already have the possibility to use a local version of DynamoDB. It is simple a downloadable version that you can run locally for development and testing purpose. Starting from the 9.1.0 version of the (Aspire.Hosting.AWS NuGet Package)[https://www.nuget.org/packages/Aspire.Hosting.AWS], you also have the option to integrate DynamoDB in your infrastructure.
Following the code that we have seen in the previous post, we can open our AppHost project and write the following C# code in Program.cs:
using Aspire.Hosting.AWS.DynamoDB;
...
var builder = DistributedApplication.CreateBuilder(args);
var localDynamoDB = builder.AddAWSDynamoDBLocal("MyLocalDB");
builder.Build().Run();
Obviously, we can create a dependency by using the WithReference and WaitFor methods, to instruct Aspire that a project, for example ApiService, must wait for the DynamoDB service to be in state READY before starting:
var builder = DistributedApplication.CreateBuilder(args);
var localDynamoDB = builder.AddAWSDynamoDBLocal("MyLocalDB");
builder.AddProject<Projects.AspireOnAWS_ApiService>("api")
.WithExternalHttpEndpoints()
.WithReference(localDynamoDB)
.WaitFor(localDynamoDB);
builder.Build().Run();
Now you can run your project again and look, there is a new kid in town:
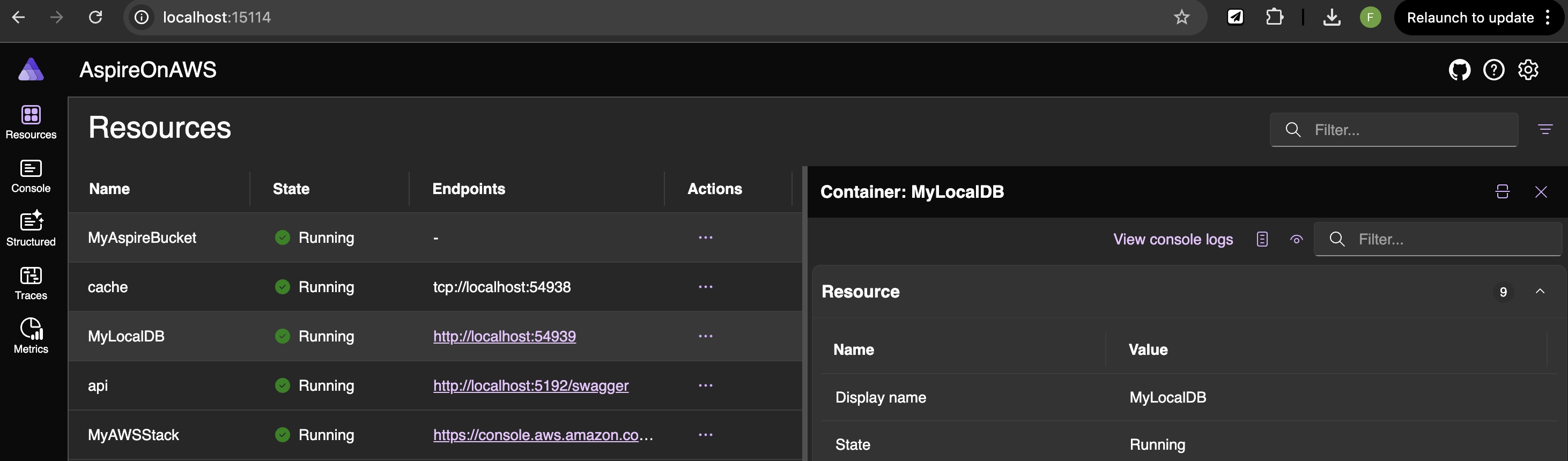
Use DynamoDB Local
To use DynamoDB in ApiService project, you can simply reference the AWSSDK.DynamoDBv2 from the AWS SDK and use the following code:
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
Keep in mind that is very important to not set RegionEndpoint. If no Region is provided, the SDK will search the environment for configuration details that define the location of the DynamoDB service. Furthermore, the Service-specific endpoints feature provided by AWS SDKs allows setting an endpoint by using an environment variable.
The AWS_ENDPOINT_URL_DYNAMODB environment variable will be set in the local container and it is injected to the .NET project by using the WithReference method call. That’s magic!
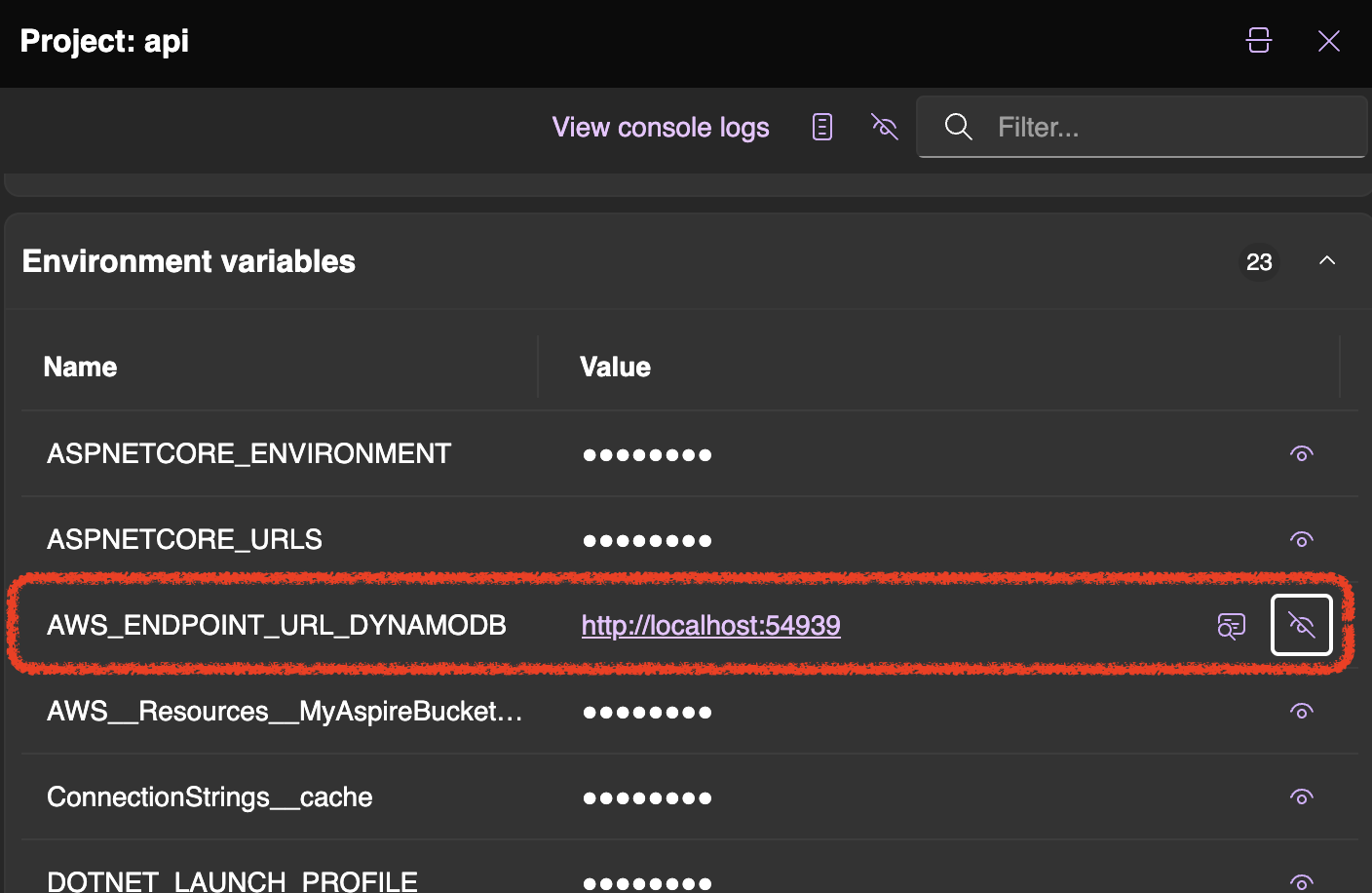
Now you can use DynamoDB also with local environment with very minimal impact on code.
Conclusion
.NET Aspire is becoming a very big asset in our developer portfolio. We are looking forward to the new feature that will be developed and integrated also in the AWS package. I’ll write again about that. In the meantime, let me know your experience and what you would like to have in the package.
Enjoy!
10 Jan 2025

Leggere 12 libri in 12 mesi. Era l’obiettivo che mi ero posto esattamente un anno fa. Obiettivo miseramente fallito!
Più o meno fino a Maggio/Giugno sono riuscito a mantenere un ritmo costante, ma per diverse motivazioni nella seconda metà dell’anno il passo non è stato lo stesso e mi sono trascinato alcuni libri.
Di seguito la lista con i libri letti e quelli mancanti:
Sei libri su dodici è un buon risultato, ma l’obiettivo non è stato raggiunto. Ad ogni modo, quest’anno riproverò con una nuova lista di 12 libri, in parte residuo di quelli non letti lo scorso anno, con l’integrazione di alcune novità.
A presto con la lista dei libri del 2025!
20 Nov 2024
Introduction
Modern distributed applications rely on a complex ecosystem of services to function effectively. From Redis for caching to OpenTelemetry for monitoring, and database options like PostgreSQL or MongoDB, managing these components presents significant challenges, especially when deploying to cloud platforms like AWS or Azure. To face
This article explores how .NET Aspire empowers developers to build and deploy cloud-native applications within the AWS ecosystem. We’ll demonstrate implementation using Visual Studio Code, though the principles apply equally to other development environments like Visual Studio or JetBrains.
What is .NET Aspire
.NET Aspire is not a new framework or a technology, it is a set of pillars that enable cloud-ready application development. It is delivered through a collection of NuGet packages that make it easier to develop, integrate, and orchestrate distributed applications comprising many small, interconnected services.
Aspire is based on the following three main pillars:
- Orchestration: Tools for running and linking multiple projects and their dependencies, make it easy to manage complex applications.
- Integrations: NuGet packages for popular services such as Redis and Postgres, with standardised interfaces for consistent and seamless connectivity.
- Tooling: Project templates and tools for Visual Studio and the .NET CLI, making it easy to create and interact with .NET Aspire projects.
These three pillars of Aspire provide a simplified and enhanced productivity environment for building, orchestrating and managing complex distributed applications.
If you’re interested in learning more about .NET Aspire check this overview https://learn.microsoft.com/en-us/dotnet/aspire/get-started/aspire-overview.
Set up your environment
To be able to work with .NET Aspire and AWS, and follow all the info described in this article, you need to have:
- .NET 8.0 or .NET 9.0
- An OCI-compliant container runtime, such as Docker Desktop or Podman
- Visual Studio Code with C# Dev Kit: Extension
- AWS .NET SDK
Build your .NET Aspire project
First of all, we’ll proceed by creating a .NET Aspire project. Before that, we should make sure that we have the latest versions of .NET workloads. To do that, we can open the terminal and write:
Then we can install, or update, the latest Aspire project templates:
dotnet new install Aspire.ProjectTemplates
Now, we can go to our project folder and write the following command to create our first Aspire solution:
The above command will create a .NET solution with basically two projects:
- a .NET AppHost project: this .NET project serves as the blueprint, defining all the individual parts of your distributed application and their interconnections.
- a .NET service defaults project: acts as a central hub for defining default settings
A .NET Aspire project’s core component is the AppHost project. In this project, we are going to define all the components that will run in our application environment. For example, if we need a Redis cache, as mentioned before, we will write the following code into the Program.cs file:
var builder = DistributedApplication.CreateBuilder(args);
builder.AddRedis("cache");
builder.Build().Run();
This is the center of our application. We can instruct how the application network should work and the connection between every service inside the AppHost project, following the basis of IaC (Infrastructure as Code) principle.
Now, we can proceed by adding the services that we want to run. For example, if we need to add a WebAPI, we should first create a project, and then add to the AppHost solution. Let’s see how we can do it by using dotnet CLI:
dotnet new webapi -o AspireOnAWS.ApiService -n AspireOnAWS.MyApiService
dotnet sln add AspireOnAWS.ApiService/AspireOnAWS.ApiService.csproj
Nothing new? That’s right. But, if we want to use the newly created project directly into the AppHost, we should add it as Project Reference:
dotnet add AspireOnAWS.AppHost/AspireOnAWS.AppHost.csproj reference AspireOnAWS.ApiService/AspireOnAWS.ApiService.csproj
Now we can use the project in the Program.cs. Let’s see the updated code:
var builder = DistributedApplication.CreateBuilder(args);
var cache = builder.AddRedis("cache");
builder.AddProject<Projects.AspireOnAWS_ApiService>("api")
.WithExternalHttpEndpoints()
.WithReference(cache)
.WaitFor(cache);
builder.Build().Run();
The above code adds two projects to the AppHost: the Redis cache, as showed before, and the ApiService. Since the ApiService project requires the Redis cache to run properly, we need to declare a reference by using the WithReference method, and a run dependency by using WaitFor. The latter means that we need to wait that the Redis cache service is ready before start the ApiService.
Run your .NET Aspire project
By simply executing dotnet run, we can now see the results:
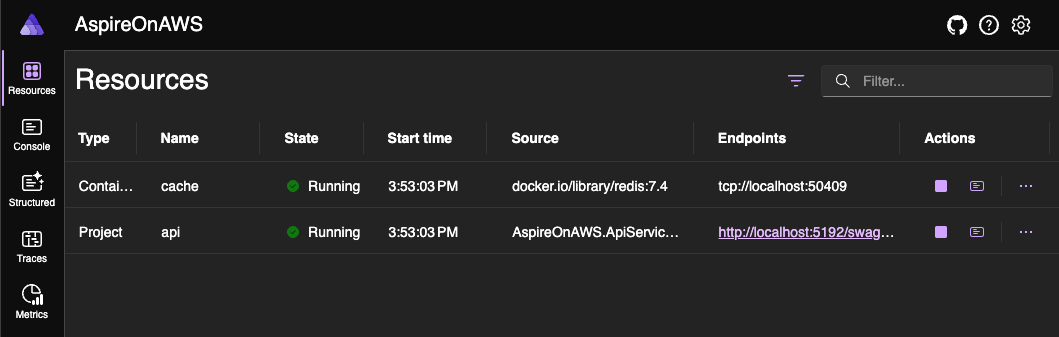
What happens in the middle? .NET Aspire requests execution of a container based on Redis image. If this is not available locally, it tries to download from the registry (!). When the image is available, a container instance is built and run. Easy.
Ready for AWS
We had just seen how to create a .NET Aspire solution and connect it with a pre-built service. Now, we are ready to see how we can interact and use AWS to run our solution.
Following the IaC rule, with .NET 9, AWS introduces the possibility of using the AWS Cloud Development Kit (CDK) in a .NET Aspire project. A big improvement that allows building applications by defining your AWS resources directly in code. CDK is a coding abstraction built on top of CloudFormation. You can define your infrastructure using your preferred language, and CDK will automatically generate a CloudFormation template.
First of all, we should add the Aspire.Hosting.AWS package to our AppHost project:
dotnet add package Aspire.Hosting.AWS
Now we can start using AWS CDK to configure the services that we would like to use. For example, if we want to use a S3 Bucket, we can add it in our AppHost by using the following code:
var builder = DistributedApplication.CreateBuilder(args);
var cache = builder.AddRedis("cache");
var stack = builder.AddAWSCDKStack("MyAWSStack");
var bucket = stack.AddS3Bucket("MyAspireBucket");
builder.AddProject<Projects.AspireOnAWS_ApiService>("api")
.WithExternalHttpEndpoints()
.WithReference(cache)
.WaitFor(cache)
.WithReference(bucket)
.WaitFor(bucket);
builder.Build().Run();
As seen before, also in this case by using WithReference we are declaring that the ApiService project should be able to see and use the S3 bucket. Futhermore, the WaitFor indicates that ApiService can be executed only when the S3 bucket service will be ready.
Resources created with these methods can be directly referenced by project resources and common properties like resource names, ARNs or URLs will be made available as configuration environment variables. The default config section will be AWS:Resources, this means that we can access to our bucket by using configuration["AWS:Resources:MyAspireBucket:BucketName"]. For example, in our ApiService, we can write the following code to retrieve the bucket name and comunicate with S3:
app.MapGet("/weatherforecast", async ([FromServices] IAmazonS3 s3client, IConfiguration configuration) =>
{
// code omitted ...
PutObjectRequest request = new PutObjectRequest
{
BucketName = configuration["AWS:Resources:MyAspireBucket:BucketName"],
Key = "WhetherForecast.json",
ContentType = "application/json",
ContentBody = JsonConvert.SerializeObject(forecast)
};
await s3client.PutObjectAsync(request);
// code omitted ...
})
Executing that code will show the following dashboard:
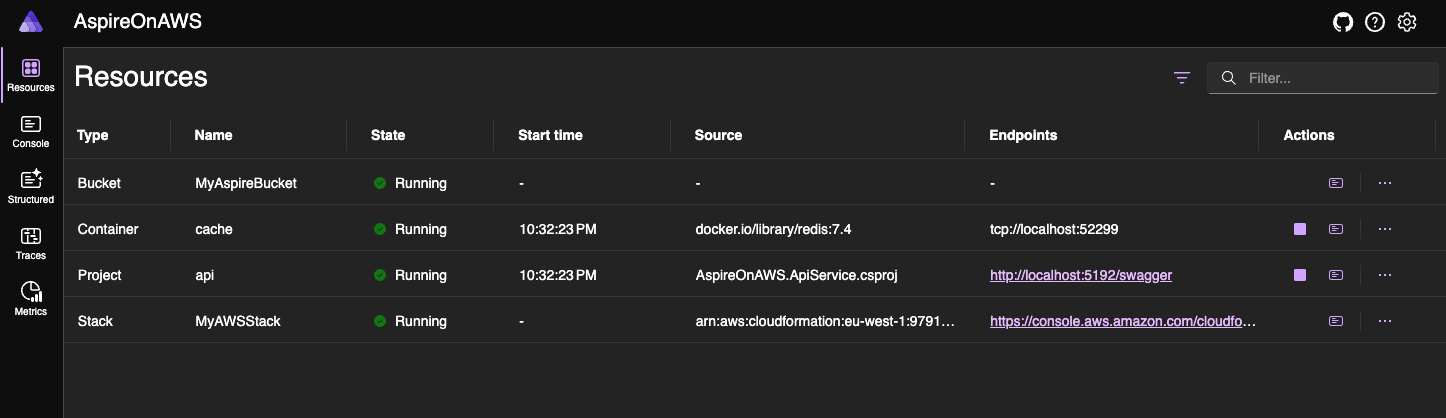
Test your code
We can now execute the Swagger UI and test the service by executing the GET /weatherservice. As we can see after execution, now the result of the API will be written in a S3 Bucket. If we open the AWS console, in Cloud Formation section we can now see the related, and just created, AWS CloudFormation Stack:

By selecting the MyAWSStack and navigating into the Resources, we can see the MyAspireBucket resource:
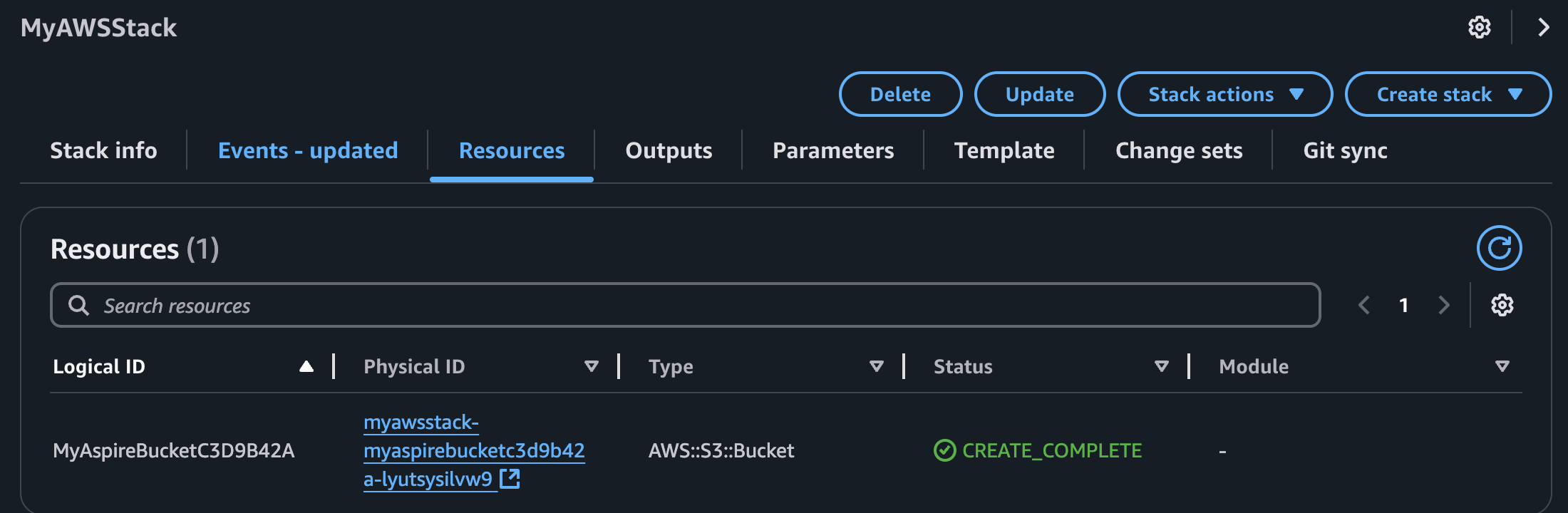
How is this possible? Well, the Aspire.Hosting.AWS also includes and runs the CDK code under the hood. So when you run your application, even locally, the package will create the required AWS infrastructure for you. And that’s a great thing!
Conclusion
In this first post we have seen what .NET Aspire is and how we can use it in combination with AWS resources by using the AWS CDK. In the next few posts, we will look at additional ways to use the AWS .NET Aspire integration in our solutions.
Enjoy!
27 Feb 2024
In the last post we talked about CQRS and how it is possible to implement it in AWS by using .NET and taking advantage from using all the power of the Cloud Native approach.
The proposed solution comes with a big limitation: it is only possible to subscribe 2 different Lambda functions to one DynamoDB Stream. Obviously, this works fine if we don’t need to build more than two different read models, but if this is the case, how we can overcome the limit?
The idea here is to use another service to propagate the event to the different subscribers. We have a couple of different options:
- Simple Notification Service (SNS): a service designed to send asynchronous notifications;
- EventBridge: a service useful to send real-time notifications;
One service to rule them all
In our simple use case, we need to asynchronously update all the consumers that want to be notified when something in the Product table changes. We doesn’t have complicated rules and the application doesn’t require to manage complex processing. This means that SNS fit perfectly for our needs. So, let’s see how to integrate in our application.
First of all, we need to update our schema to include the new model. At the moment, is not possible to subscribe SNS directly to DynamoDB Stream (which is possible with EventBridge), so we need to use something else to process the message from DynamoDB and send it to SNS. As already done, we can still use a Lambda function, which will be responsible to receive the notification from DynamoDB Stream and send to the SNS. On the other side, the notification will be distributed to different consumers by the SNS, and we can still use a set of Lambda functions to process the notification according to the read model needs. This set of Lambda functions will adapt the input message to the different read models.
Following, you can see the updated schema:
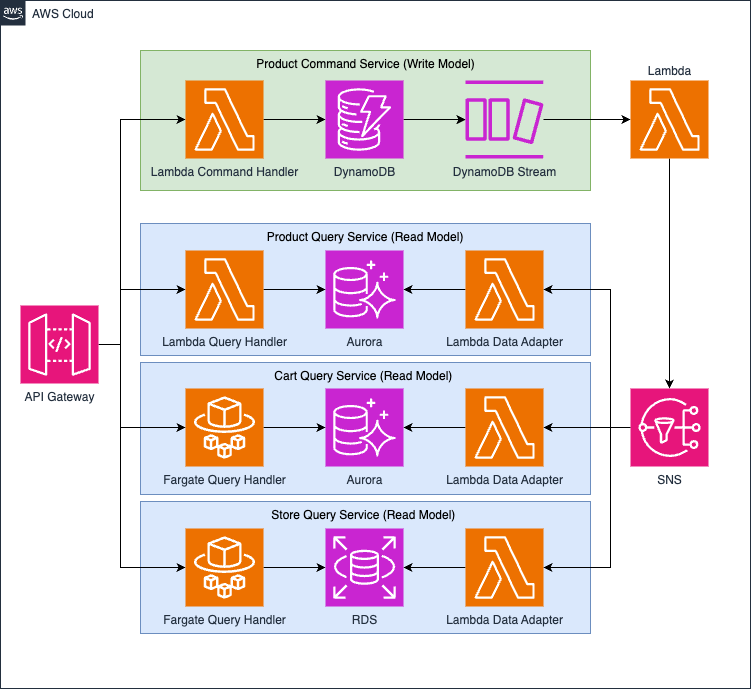
Just to provide you a more complete idea of the possibilities available with this approach, in the above architecture schema I’ve included also different types of Query Handlers and Storage. You can build an handler or a storage by using the most useful technology that fits better the specific domain. As an example, the schema show a Fargate solution in both Cart Query Service and Store Query Service, with two different storage: Aurora and RDS.
Connect your Simple Notification Service
In the previous post we have seen how to connect a Lambda function to the DynamoDB Stream. By using the same approach, we can configure a SNS as destination of the Lambda function. So, we can go to our Lambda and update it according to the following code (full code on previous post):
Product product = new Product
{
ProductId = Convert.ToInt32(newImage["ProductId"].N),
Name = newImage["Name"].S,
Price = Convert.ToDecimal(newImage["Price"].N)
};
string productJson = JsonSerializer.Serialize(product);
var publishRequest = new PublishRequest
{
TopicArn = "arn:aws:sns:...:ProductUpdated",
Message = productJson
};
await snsClient.PublishAsync(publishRequest);
But, first of all, we need to create the SNS topic and than configure the AWS Lambda that needs to receive the published message:
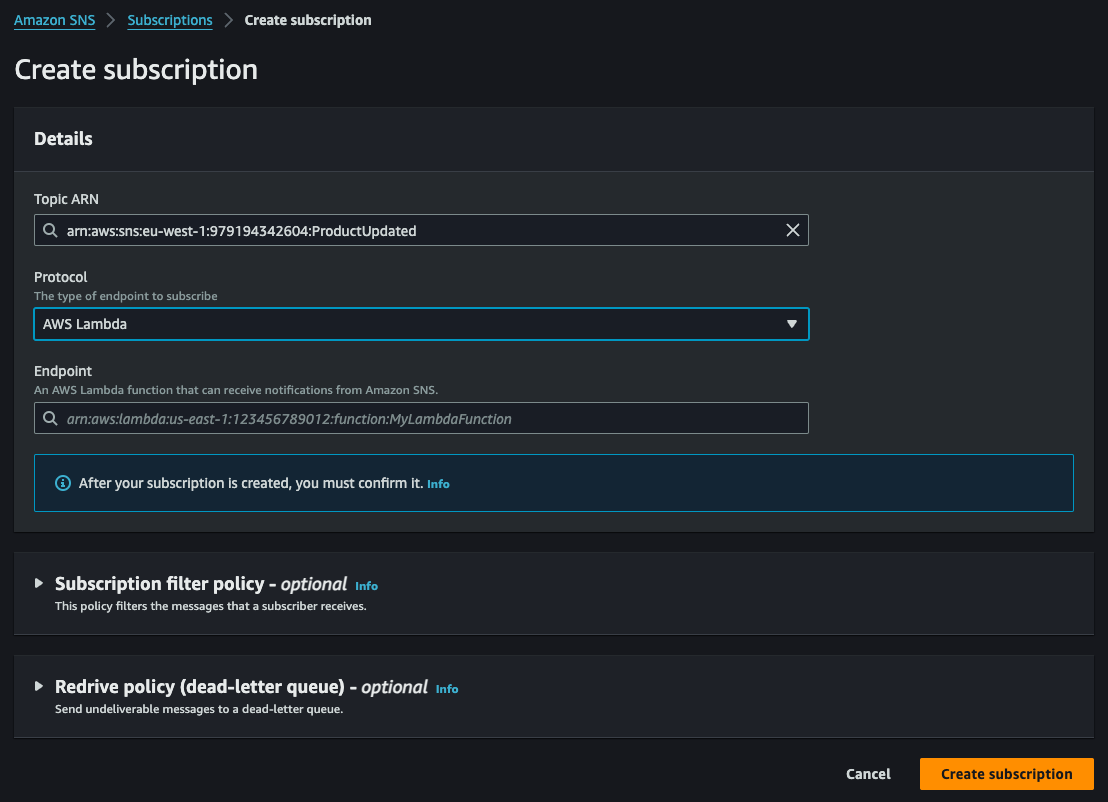
Finally, we can rewrite the Lambda function to receive the message from SNS and than write into the target database:
[assembly: LambdaSerializer(typeof(Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer))]
public class Function
{
private readonly AmazonSNS _snsClient;
public Function()
{
_snsClient = new AmazonSNS(); // Replace with your SNS client configuration if needed
}
public async Task FunctionHandler(SNSEvent snsEvent, ILambdaContext context)
{
foreach (var record in snsEvent.Records)
{
var snsRecord = record.Sns;
Product product = JsonSerializer.Deserialize<Product>(snsRecord.Message);
using (MySqlConnection connection = new MySqlConnection(connectionString))
{
connection.Open();
using (MySqlCommand cmd = connection.CreateCommand())
{
cmd.CommandText = "INSERT INTO Product (ProductId, Name, Price) VALUES (@ProductId, @Name, @Price)";
cmd.Parameters.AddWithValue("@ProductId", product.ProductId);
cmd.Parameters.AddWithValue("@Name", product.Name);
cmd.Parameters.AddWithValue("@Price", product.Price);
cmd.ExecuteNonQuery();
}
}
}
}
}
Conclusion
As show in this post, it is really easy to use that approach with the different set of services available in AWS. In the next post, we’ll see another way to reach out the same result.
Enjoy!
20 Feb 2024
One of the most talked about and appreciated patterns in recent years is undoubtedly CQRS: Command-Query Responsibility Segregation. Its potential is offset by implementation complexity, which is too often underestimated in the design phase. Moreover, we too often approach the pattern without a real need, lured by the promise of potential scalability but underestimating its implementation and maintenance costs.
But let’s take a step back and first understand what scenario CQRS proposes to solve and why we decided to talk about it today.
What is CQRS
CQRS is an architectural pattern suitable for developing applications that must provide a high level of scalability while still handling high volumes of traffic and data. The primary use case involves applications that need to handle significantly more read requests than read requests.
The underlying concept is simple: the logical, but not limited to, separation of write requests from read requests. Basically, instead of the usual, single model for all CRUD-type operations, there is the creation of two separate models that are particularly optimized for the different purposes they must serve.
This split allows for a streamlined, simplified model tailored to each specific read operation, leaving the complexity of business logic on the write operations. The end result is a flexible application that allows the two models to scale independently. In this way the two worlds are completely parallel, perfectly designed for their purpose, even going so far as to use two completely separate databases.
In this first article, therefore, we are going to explore the possibilities offered by the AWS cloud to develop a simple solution by applying the CQRS pattern, focusing mainly on the data storage part.
CQRS in Cloud-Native mode with AWS
Let us start by defining the ideal Cloud-Native technology, in our context, to implement the write model. Our requirement is to save an entity or, rather, the state of an aggregate in our storage and notify that this operation was successful and the state of our application has changed. AWS offers several storage technologies, but to take full advantage of the ability to historicize the entire payload, the best choice can only be DynamoDB.
DynamoDB, in fact, is the leading NoSQL storage solution offered by AWS. It is designed to offer high performance, allows for fully automatic scaling, effectively handling large volumes of data while offering low latency. Most importantly, it is relatively inexpensive.
Having chosen the database for the write model, let us now focus on the read model. In the introduction, we described the possibility of using different databases for the two models. For the read model, we need to build an efficient database that can support the different queries that can be performed, and most importantly, scale horizontally where needed, without intervening at the application level. Amazon Aurora responds worthily to these characteristics. It is a MySQL- and PostgreSQL-compatible database that has the attractive feature of an easy replication mechanism.
Finally, we need to define how to transfer data from the write model to the read model. The strategies can be different, but to take full advantage of the Cloud’s capabilities, AWS provides us with an interesting service: DynamoDB Stream. Basically, by enabling DynamoDB Stream on a DynamoDB table, we can generate an event stream to which a Lambda function can then be hooked. The idea then is that, with each write to the table, an event is generated that is in turn captured by a Lambda function.
It will then be the job of the Lambda function to extract the necessary information to create the write pattern and populate the corresponding database.
The diagram below describes the desired architecture of our solution:
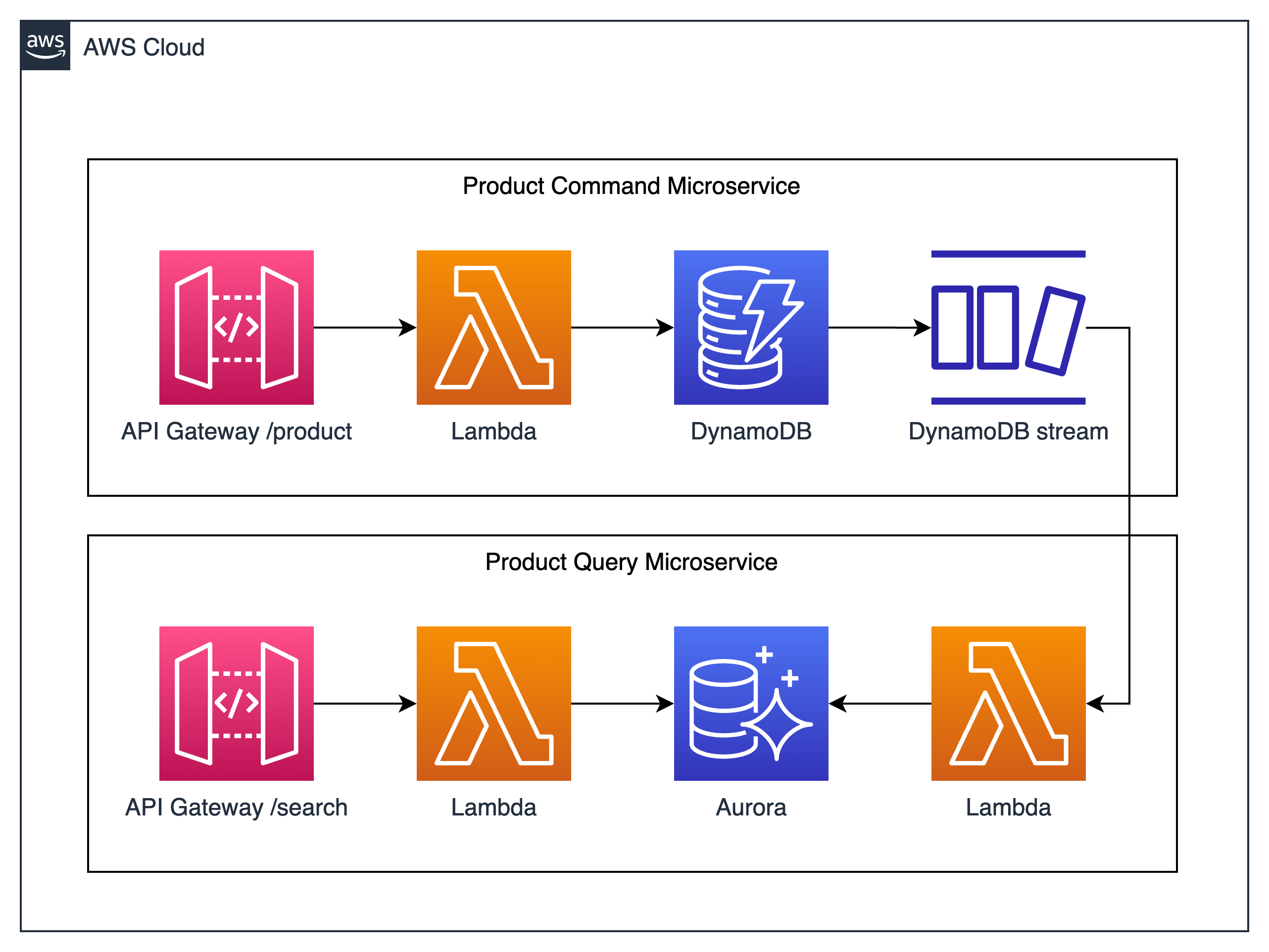
Il nostro modello di scrittura e DynamoDB
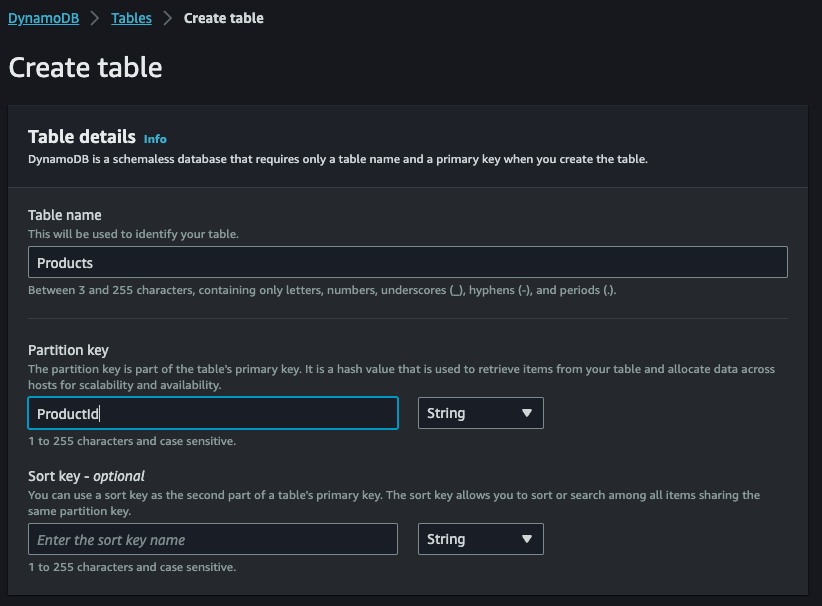
Prerequisite of our solution, as shown in the diagram above, is the creation of a DynamoDB table and an Amazon Aurora database, as well as the development of the necessary AWS Lambda functions. We then start with the creation of the table. We then access the AWS console, and from there the DynamoDB service management page, and click on Create Table:

Now we can set table name on Products and Partition key on ProductId, and finally we can click on Create table:
Let us now proceed with writing our AWS Lambda function. If we have not already installed the Amazon Lambda Templates, we use the dotnet command to proceed with the installation:
dotnet new install Amazon.Lambda.Templates
In order to create Lambda functions, we must also proceed with the installation of the .NET Global CLI Tools:
dotnet tool install -g Amazon.Lambda.Tools
Finally we proceed with the creation of the project:
dotnet new lambda.EmptyFunction --name ProductCommandFunction
Within the project, we define our simple model for saving a product:
[DynamoDBTable("Products")]
public class Product
{
[DynamoDBHashKey]
public int ProductId { get; set; }
[DynamoDBProperty]
public string Name { get; set; }
[DynamoDBProperty]
public decimal Price { get; set; }
[DynamoDBProperty]
public bool OutOfStock { get; set; }
}
As a result, the Lambda function that does the saving appears to be very simple indeed:
using Amazon.Lambda.Core;
using Amazon.Lambda.Serialization.SystemTextJson;
using Amazon.DynamoDBv2;
using Amazon.DynamoDBv2.DataModel;
using System;
using System.Threading.Tasks;
[assembly: LambdaSerializer(typeof(DefaultLambdaJsonSerializer))]
public class Function
{
private static AmazonDynamoDBClient _dynamoDbClient;
private static DynamoDBContext _dbContext;
static Function()
{
AmazonDynamoDBConfig clientConfig = new AmazonDynamoDBConfig
{
RegionEndpoint = Amazon.RegionEndpoint.YOUR_REGION
};
_dynamoDbClient = new AmazonDynamoDBClient("YourAccessKey", "YourSecretKey", clientConfig);
_dbContext = new DynamoDBContext(_dynamoDbClient);
}
public async Task<string> FunctionHandler(Product inputProduct)
{
await _dbContext.SaveAsync(inputProduct);
}
}
Our writing model and Amazon Aurora
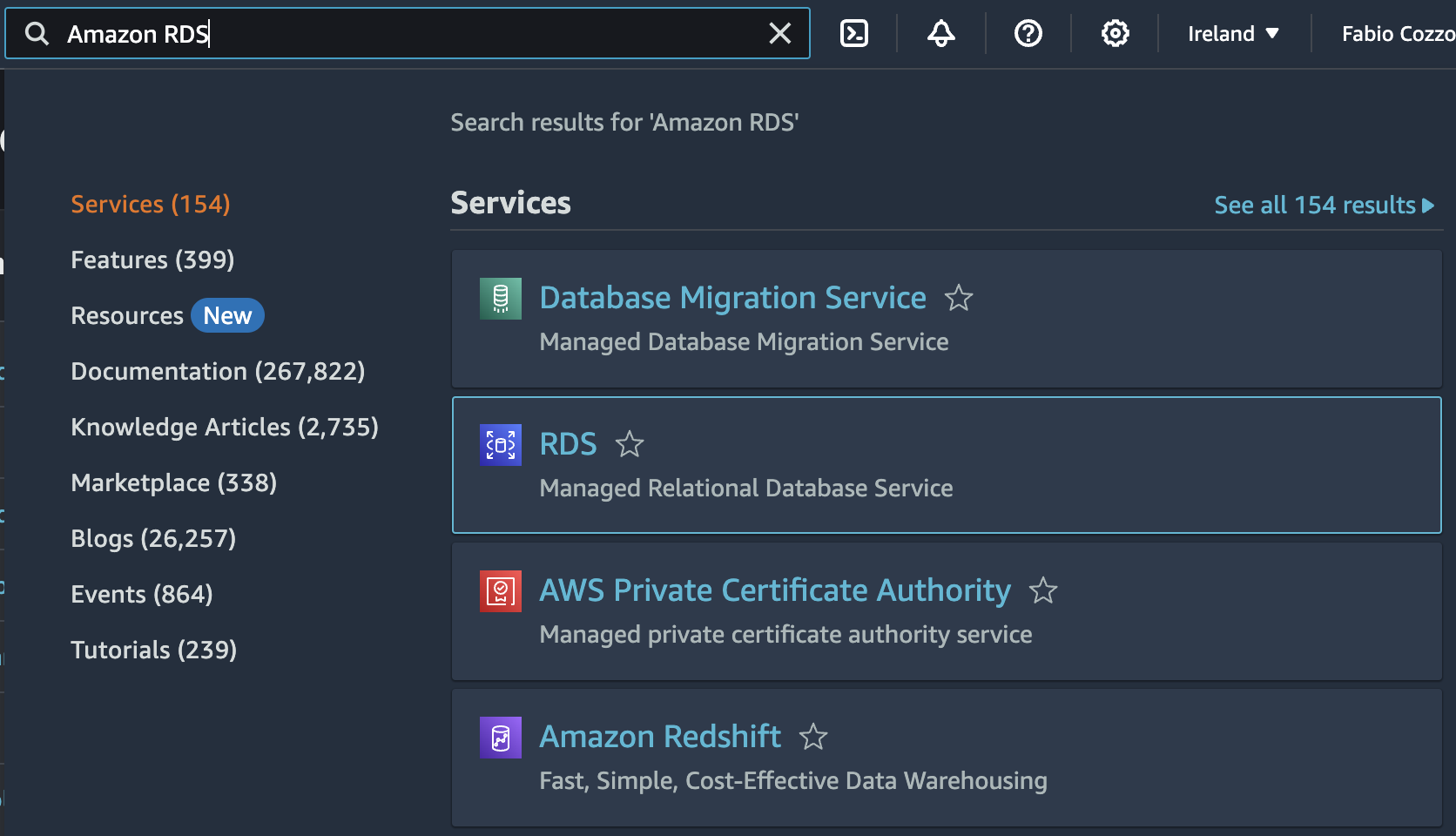
Having created and prepared the read model (Query), we now need to create the Amazon Aurora database that we will use as the basis for the write model (Command). We have already anticipated how Amazon Aurora was the choice. To create it, therefore, we access the AWS console and select Amazon RDS, also simply using the search box, as shown below:
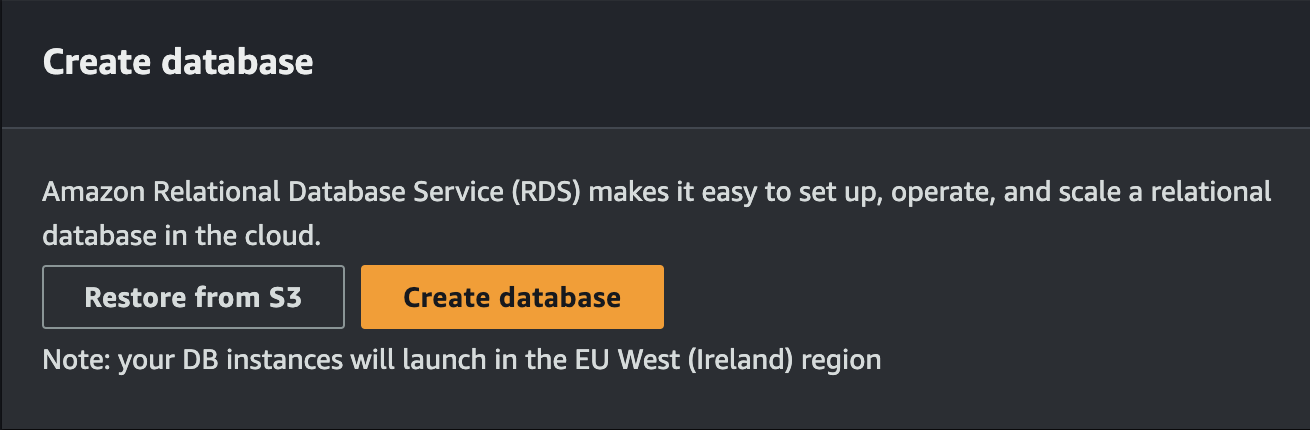
From the Create database section, we click on the defined button to proceed with the creation of our database:
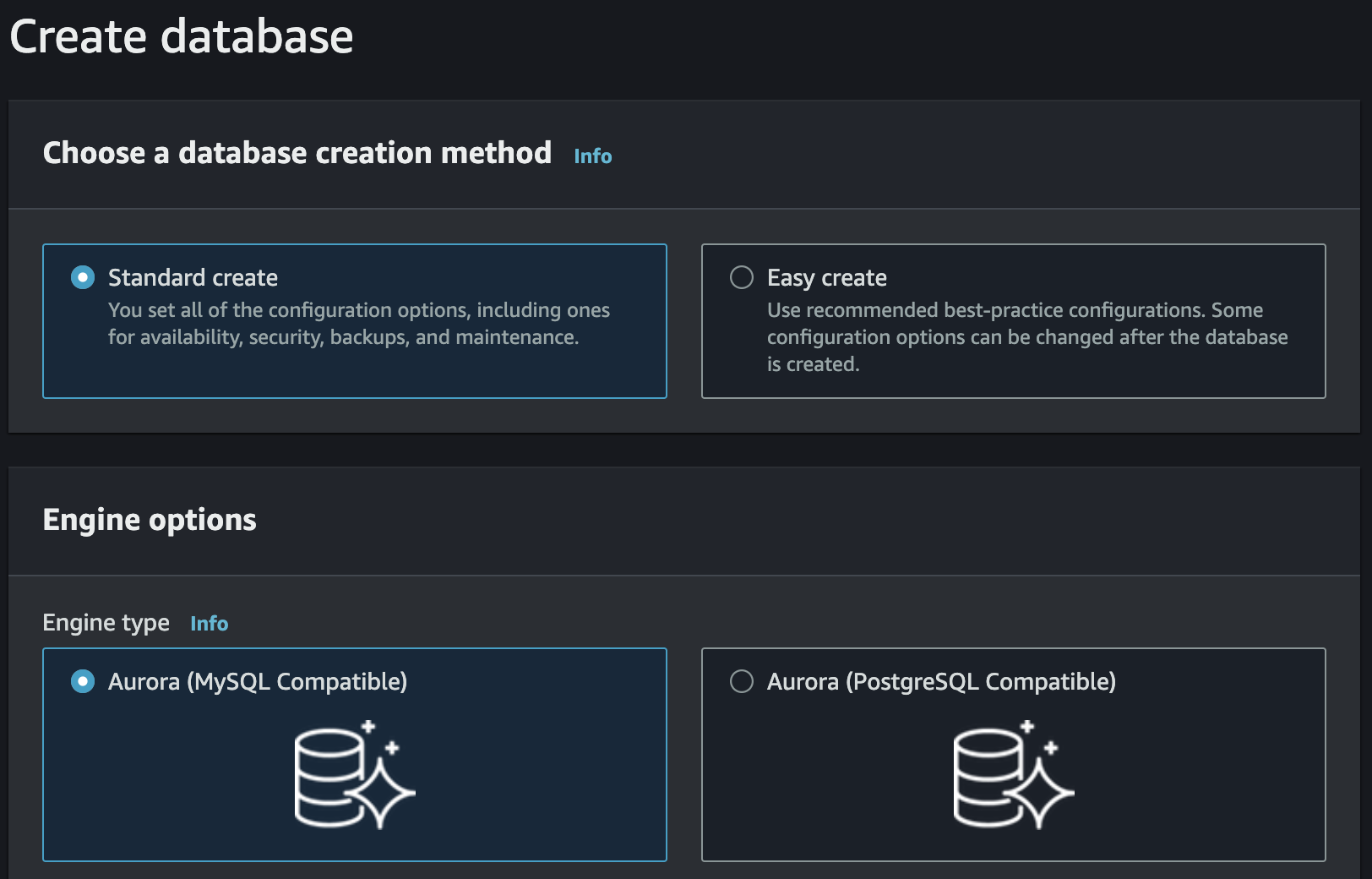
We choose Amazon Aurora as the database engine and the engine we want to use, in our case we opt for compatibility with MySQL:
For the purpose of this article, we can leave the default settings and possibly choose a more suitable name to assign to our database.
We then click on Create database to generate our storage. When finished, we will have a situation like the following:

Now our read database, which will simply contain the product list, is ready to be used. The next step is to connect the two databases to generate the read table from the write table. For this, we can take advantage of a native feature of DynamoDB called DynamoDB Stream.
Let’s create our DynamoDB Stream
Having created our table in DynamoDB, we must now enable the stream that will then allow us to capture write events and eventually redirect them to a dedicated Lambda function.
But what is a DynamoDB stream? We can define it as a stream of events, sorted by their natural order, generated from operations performed on the table such as insert, modify or delete.
This allows us to intercept what is happening on the DynamoDB table and act accordingly.
We then create our DynamoDB Stream. From the management console, we access our previously created Products table and, in the Exports and streams section, click on the Turn on button at DynamoDB stream details:
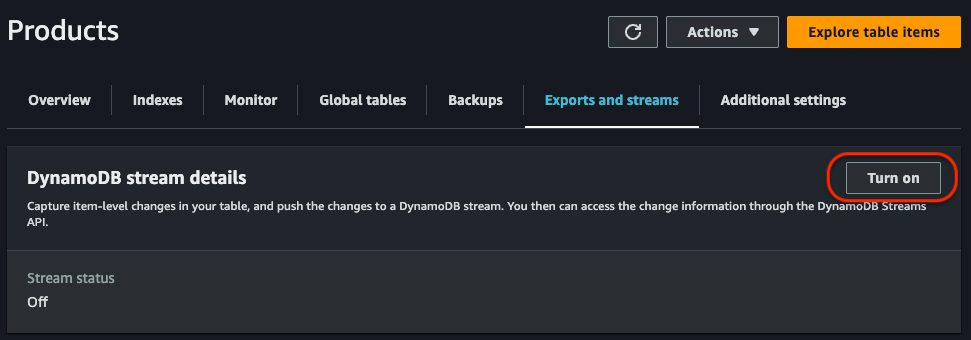
We then select New and old images in order to get the new record directly, as a result of the change made on the database:
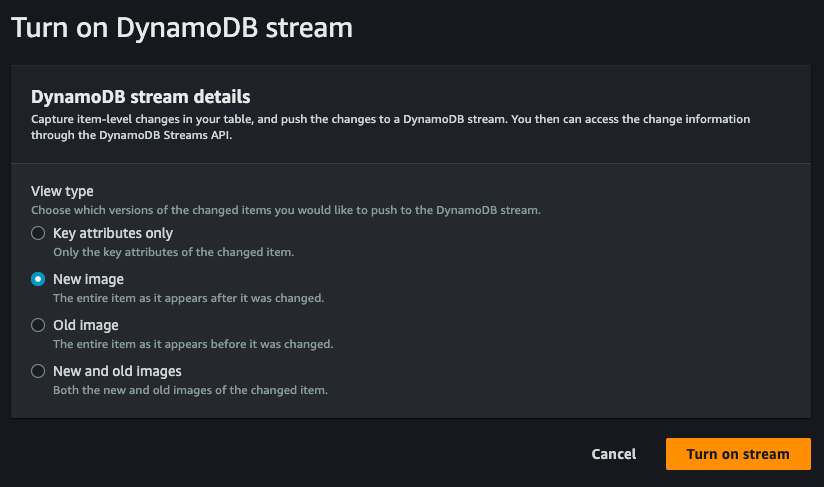
At the same time that the DynamoDB stream is enabled, an ARN will also be created, a unique identifier valid within AWS that is needed to locate resources and connect them to each other. It will in fact come in handy in the next step when we go to create the Lambda function that will take care of generating the data in the write tables.
A Lambda function to generate the reading model.
Having set everything up for writing, we now proceed to generate our read model. We then create a new AWS Lambda project
dotnet new lambda.EmptyFunction --name ProductHandlerFunction
The task of this function is relatively simple: handle the insert, edit, and delete events of an item in the DynamoDB Products table and write it to an Amazon Aurora table. To do this, we modify the Function class in the Function.cs file as shown below:
[assembly: LambdaSerializer(typeof(Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer))]
public class Function
{
private readonly string connectionString;
public Function()
{
// Replace these values with your Aurora database connection details
string serverName = "your-aurora-server-name";
string dbName = "your-aurora-database-name";
string username = "your-aurora-username";
string password = "your-aurora-password";
connectionString = $"Server={serverName};Database={dbName};User ID={username};Password={password};";
}
public void FunctionHandler(DynamoDBEvent dynamoEvent, ILambdaContext context)
{
foreach (var record in dynamoEvent.Records)
{
Dictionary<string, AttributeValue> newImage = record.Dynamodb.NewImage;
if (newImage != null)
{
Product product = new Product
{
ProductId = Convert.ToInt32(newImage["ProductId"].N),
Name = newImage["Name"].S,
Price = Convert.ToDecimal(newImage["Price"].N)
};
using (MySqlConnection connection = new MySqlConnection(connectionString))
{
connection.Open();
using (MySqlCommand cmd = connection.CreateCommand())
{
cmd.CommandText = "INSERT INTO Product (ProductId, Name, Price) VALUES (@ProductId, @Name, @Price)";
cmd.Parameters.AddWithValue("@ProductId", product.ProductId);
cmd.Parameters.AddWithValue("@Name", product.Name);
cmd.Parameters.AddWithValue("@Price", product.Price);
cmd.ExecuteNonQuery();
}
}
}
}
}
}
For the correct execution of the Lambda function, the following packages must be installed:
dotnet add package AWSSDK.Extensions.NETCore.Setup
dotnet add package Newtonsoft.Json
dotnet add package MySql.Data
dotnet add package AWSSDK.DynamoDBv2
dotnet add package Amazon.Lambda.DynamoDBEvents
Having finished the development of our Lambda function, we can now publish it to AWS, as we saw earlier, with the command:
dotnet lambda deploy-function ProductHandlerFunction
After choosing an appropriate name for the IAM role, we select option 2 AWSLambdaInvocation-DynamoDB as the policy to apply for our purpose:

Upon completion we will find our Lambda function in the relevant section on AWS Console:
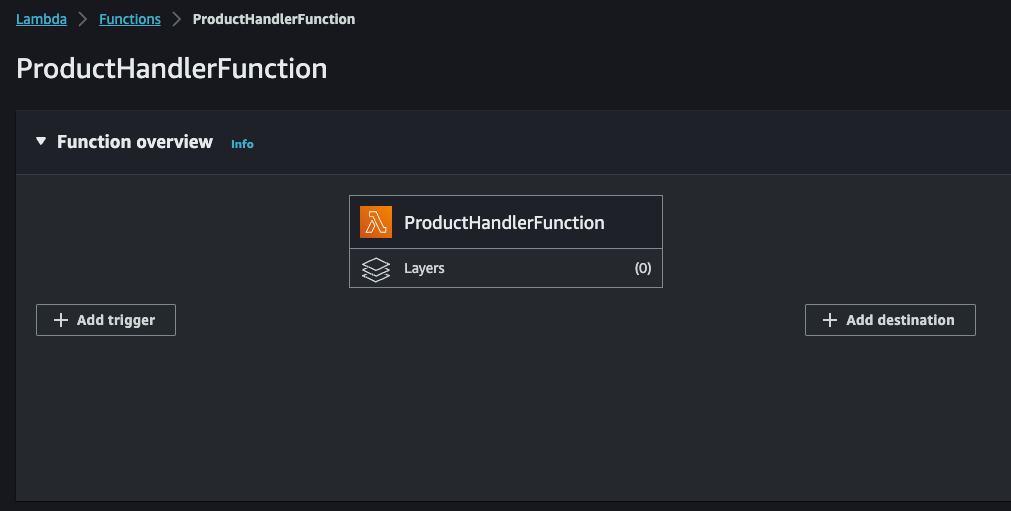
We can now click on Add trigger to add DynamoDB stream as the source of our Lambda function:
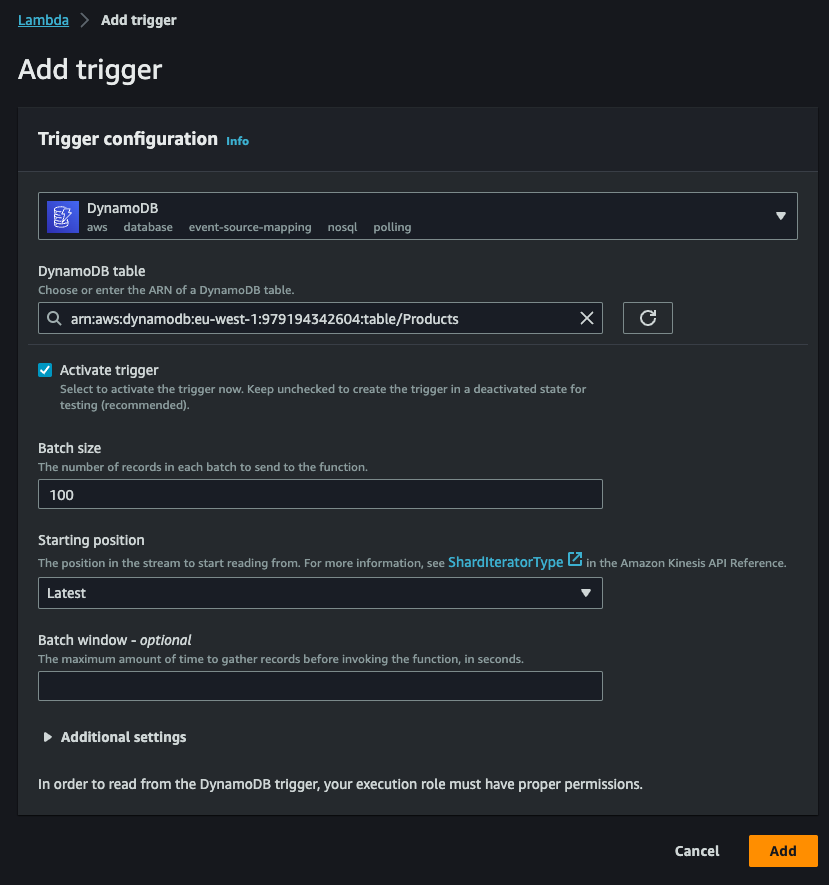
The trigger, as shown above, will allow us to intercept any write event on the Products table in DynamoDB. Finally, the Lambda function will take care of transforming the received information in the most appropriate way and save it to the Amazon Aurora database, ready to be used later by the read model.
The choice of Amazon Aurora as the repository for read operations is not accidental. As anticipated, Amazon Aurora allows the configuration of read replicas, mirror copies of the primary database whose purpose is to improve system performance by allowing multiple users to access data simultaneously.
When a read operation is performed on a replica, the load is distributed between the primary database and the read replicas, thus reducing the load on the primary database and allowing more read requests to be handled.
The Amazon Aurora read replicas are synchronized continuously with the primary database to ensure that the data is always up to date. This ensures that, in the event of a loss, one of the read replicas can be promoted to the primary database to ensure continuity of service.
Configuring Amazon Aurora and the read replicas
The replication capability of Amazon Aurora can thus be an additional weapon to enable highly scalable and performant services.
Configuration of Amazon Aurora and read replicas can be done by directly accessing the Amazon RDS service and selecting the previously created Aurora database:

If not already done, add a reader node by clicking on Actions and then on Add reader:
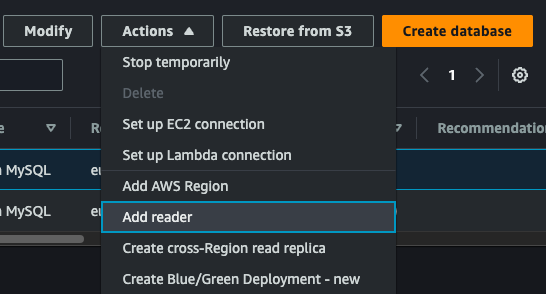
We assign it a name, check all the creation parameters, and confirm the creation. With this action we can create several read replicas and increase the scalability of our solution. In addition, we can also take advantage of the auto scaling capability by configuring, again from the Actions menu, auto scaling for read nodes based on CPU utilization or number of connections, also setting the minimum and maximum nodes to be used.
Conclusion
In this first article, we have seen how we can manage two different storage to support an architecture based on the CQRS model, with the ability to replicate and adapt the data appropriately based on the different needs of the read and write models.
AWS offers important solutions that can be leveraged to achieve the desired performance and scalability. Of course, it is always a good idea to keep a close eye on the costs arising from each and every choice we place in our architectural solutions.
In the next articles we will see how to improve the solution for which we have just laid the foundation.
As always, any feedback is welcome!
Enjoy!
15 Feb 2024

Primo libro, prima recensione. O meglio, le mie sincere impressioni. Innanzitutto ho scelto la versione italiana del libro per avere una lettura più semplice ed agevole, senza il sovraccarico cognitivo derivante dalla necessaria “traduzione contestuale”. Scelta personale, ovviamente, e per me più che centrata. Dispiace che la versione italiana, al contrario delle altre traduzioni internazionali, abbia optato per un cambio totale di copertina, con una scelta secondo me discutibile. Ad ogni modo, a noi interessano i contenuti.
Il Libro
Il libro spiega e condivide l’approccio dell’autore, partendo da un’esperienza personale, sulla costruzione di un metodo utile per l’organizzazione della personale memoria. L’idea di base è quella di non raccogliere le informazioni “che generano una qualche emozione”, o che riteniate possano essere utili in futuro, e raccoglierle in un’area digitale, la cui funzione è, appunto, quella di un secondo cervello, al quale è possibile accedere in qualsiasi momento.
Vengono illustrati principalmente due metodi:
- il metodo CODE (Capture, Organize, Distill, Express), la sequenza di stati attraverso i quali passa ogni singolo appunto, così da prepararlo ad essere facilmente fruibile;
- il metodo PARA (Projects, Areas, Resources, Archives), utilizzato per l’organizzazione degli appunti in apposite “categorie”, così da semplificare la loro ricerca;
In che modo mi è stato utile?
L’approccio è davvero interessante. Sono costantemente alla ricerca di un metodo per la gestione dei miei appunti, ma più in generale per la gestione delle mie attività, da quelle lavorative a quelle personali. Il dover ricordare tutto non è facile. Come riportato nel libro, un articolo del New York Times stima che consumiamo quotidianamente l’equivalente di circa 34 Gigabytes. Una quantità enorme di dati che complica decisamente la loro fruizione qualitativa. Fatichiamo a districarci nella enorme mole di appunti, segnalibri, articoli nella categoria del “lo leggo dopo”, e puntualmente finiamo per perderli completamente di vista (e non leggerli mai). A quanti capita? A me spesso.
Ho quindi iniziato ad applicarlo nella pratica quotidiana. Lungi dall’esser perfetto, mi ha permesso di trovare in pochissimo tempo le informazioni di cui avevo bisogno, anche pochi minuti prima di una riunione. Davvero utile, ma serve molta disciplina e costanza nel tempo.
Conclusioni
Libro scorrevole e molto ben fatto. Non ho risentito molto della traduzione italiana, per cui lo consiglio senza dubbio, soprattutto se siete alla ricerca di un metodo o semplicemente un’ispirazione per l’organizzazione della vostra vita.
10 Jan 2024
Leggere mi ha sempre appassionato. Purtroppo nell’ultimo periodo sono stato molto discontinuo e per questo ho deciso di avviare una challenge personale e leggere “almeno” 12 libri in 12 mesi. L’obiettivo è anche quello di condividere poi una breve recensioni dei libri letti.
Di seguito la roadmap del progetto (si, si tratta proprio di un progetto, con le sue scadenze):
- Gennaio: Il tuo Secondo Cervello Tiago Forte
- Febbraio: Team Topologies Matthew Skelton, Manuel Pais
- Marzo: Le Organizzazioni Agili Carmela Flaminio
- Aprile: Fundamentals of Software Architecture Neal Ford, Mark Richards
- Maggio: Pensieri Lenti e Veloci Daniel Kahneman
- Giugno: Platform Strategy Gregor Hohpe
- Luglio: Accelerate, The Science Behind Devops Nicole Forsgren, Jez Humble, Gene Kim
- Agosto: Detto, fatto! L’arte di fare bene le cose David Allen
- Settembre: Building Micro-Frontend Luca Mezzalira
- Ottobre: Learning Domain-Driven Design Vlad Khononov
- Novembre: Atomic habits. Piccole abitudini per grandi cambiamenti James Clear
- Dicembre: Flow Architectures James Urquhart
Bonus books (ovvero, altro che vorrei leggere):
- Monolith to Microservice Sam Newman
- Software Architecture: The Hard Parts Neal Ford, Mark Richards, Pramod Sadalage & Zhamak Dehghani
- Building Event-Driven Microservices Adam Bellemare
E la lista potrebbe anche essere più lunga.
Ovviamente, come ogni roadmap che si rispetti, potrebbe subire variazioni in corso d’opera.
Let’s start reading them!
30 Dec 2023
E’ stato un anno davvero complicato. Nuove sfide lavorative e la voglia di vivere ogni momento possibile con la mia famiglia, mi hanno lasciato poco tempo da dedicare alle community. E’ una questione di priorità, direbbe qualcuno. Nulla di più vero.
Sono riuscito comunque a ritagliarmi piccoli spazi e partecipare all’Agile O’Day 2023 di Napoli con la sessione “I don’t need an Architect, I’m Agile!”, poi rivista e ampliata durante uno SmallTalk di UGIdotNET a giugno.
In entrambi i casi, l’opportunità di parlare di un argomento che mi sta molto a cuore: la Software Architecture nei contesti Agili.
Il prossimo anno sarà ancora più intenso e pieno di nuove occasioni per migliorare, crescere e sperimentare, con la promessa di riprendere a scrivere nel mio blog, o anche in altre sedi, e proseguire il lavoro fatto negli ultimi anni nelle community con rinnovato impegno e dedizione.
Buon 2024 a tutti!
10 Dec 2022
Disclaimer! This post is generated from a conversation with ChatGPT. I asked a couple of things and wait for an answer. Let’s see what happened!
Question 1: What is the better way to create a realtime distributed software architecture?
There are many different ways to create a real-time distributed software architecture, and the “best” way will depend on your specific requirements and use case. Some common approaches to creating real-time distributed systems include using message brokers, event-driven architectures, and distributed databases.
One way to create a real-time distributed system is to use a message broker, such as Apache Kafka or Amazon Simple Queue Service (SQS), to enable communication and data sharing between different components of the system. This allows each component to operate independently and asynchronously, while still being able to share data and communicate with other components in real time.
Another approach is to use an event-driven architecture, where components of the system communicate and coordinate their actions through the publication and subscription of events. This allows the system to respond to changes in data or user input in real time, without the need for continuous polling or synchronization between components.
Finally, you can use a distributed database, such as Apache Cassandra or Amazon DynamoDB, to store and manage data in a distributed and highly-available manner. This allows different components of the system to access and update the data in real time, without the need for a central point of coordination or control.
Ultimately, the best approach for your system will depend on your specific requirements and constraints, and may involve a combination of these and other techniques. It’s important to carefully evaluate your options and choose the approach that best fits your needs.
Question 2: How I can create a multi cloud realtime distributed software architecture?
To create a multi-cloud real-time distributed software architecture, you can use a combination of the techniques discussed above, such as message brokers and event-driven architectures, along with cloud-specific services and tools.
One way to create a multi-cloud real-time distributed system is to use a cloud-agnostic message broker, such as Apache Kafka, which can be deployed across multiple cloud platforms and support communication and data sharing between different components of the system. This allows you to take advantage of the benefits of multiple cloud platforms, such as flexibility, scalability, and cost-effectiveness, while still maintaining a consistent and cohesive architecture for your system.
Another approach is to use cloud-specific event-driven architectures, such as AWS Lambda and Azure Functions, to enable real-time data processing and coordination across different cloud platforms. This allows you to leverage the unique capabilities and features of each cloud platform, while still maintaining a consistent event-driven approach to your architecture.
Additionally, you can use cloud-agnostic or cloud-specific distributed databases, such as Apache Cassandra and Amazon DynamoDB, to store and manage data in a distributed and highly-available manner across multiple cloud platforms. This allows you to take advantage of the scalability and reliability of distributed databases, while still maintaining the flexibility and portability of a multi-cloud architecture.
Overall, creating a multi-cloud real-time distributed architecture involves carefully balancing the benefits and challenges of using multiple cloud platforms, and choosing the right mix of tools and techniques to support your specific requirements and use case.
Question 3: Let me know how I can use Apache Kafka from C#
To use Apache Kafka from C#, you will need to have the Apache Kafka and the .NET client for Apache Kafka, known as Confluent.Kafka, installed on your system. Once you have these, you can use the Producer and Consumer classes in the Confluent.Kafka namespace to send and receive messages from Kafka topics.
Here’s an example of how you can use these classes to send a message to a Kafka topic:
using Confluent.Kafka;
namespace ApacheKafkaExample
{
class Program
{
static void Main(string[] args)
{
// Create a new Kafka producer.
var producerConfig = new ProducerConfig
{
BootstrapServers = "localhost:9092"
};
using (var producer = new ProducerBuilder<string, string>(producerConfig).Build())
{
// Send a message to the topic.
producer.Produce("my-topic", new Message<string, string>
{
Key = "my-key",
Value = "Hello, World!"
});
}
}
}
}
This code creates a new Producer object and uses it to send a message with the key “my-key” and the value “Hello, World!” to the topic “my-topic”. The Kafka server to connect to is specified in the BootstrapServers property of the ProducerConfig object that is passed to the ProducerBuilder when creating the Producer object.
To receive messages from a Kafka topic, you can use the Consumer class in the same way. Here’s an example of how you can use this class to receive and process messages from a Kafka topic:
using Confluent.Kafka;
namespace ApacheKafkaExample
{
class Program
{
static void Main(string[] args)
{
// Create a new Kafka consumer.
var consumerConfig = new ConsumerConfig
{
BootstrapServers = "localhost:9092",
GroupId = "my-group"
};
using (var consumer = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
// Subscribe to the topic.
consumer.Subscribe("my-topic");
// Poll for messages.
while (true)
{
var message = consumer.Consume();
Console.WriteLine($"Received message: {message.Value}");
}
}
}
}
}
This code creates a new Consumer object and uses it to subscribe to the topic “my-topic”. It then enters an infinite loop and uses the Consume method of the Consumer object to poll for new messages from the topic. Whenever a new message is received, it is printed to the console.
To learn more about how to use the Producer and Consumer classes in the Confluent.Kafka namespace to interact with Apache Kafka from C#, please see the Confluent.Kafka documentation.
Conclusion
Really, really awesome.
Enjoy it at https://chat.openai.com/chat
21 Mar 2022

Serverless currently is for sure one of the most popular words of the last few years, at least in the Cloud Computing world. But, what does it mean? This is one of the most simple definitions I found:
Serverless is a cloud-native development model that allows developers to build and run applications without having to manage servers
(RedHat).
So, this means that servers are still there (fiuuu…).
Serverless doesn’t mean “without server”, but it is more related to ownership of resources, load balancing, scalability, and the other server things that a developer doesn’t need to manage. Servers technologies are abstracted away from development.
AWS currently has a lot of services useful to implement serverless applications. One of the most well knows is AWS Lambda. An AWS Lambda is composed of two-part: a function, the code and runtime that process events, and a trigger, the AWS service or application that causes the function execution. In this post we are going to see out to deploy an AWS Lambda function developed with the new .NET 6 Minimal API, using GitHub as a source repository.
Before we get into the steps, a few words about the AWS services and tools we are going to use:
- AWS Lambda: a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. One of the most important points is that you only pay for what you use, which in that case means that you only pay for the execution time. More info at the official page.
- AWS CodePipeline: a fully managed continuous delivery service. With CodePipeline you can automate the build and deploy service. Check the official page.
- AWS Lambda Tools for .NET Core: a set of commands to create and deploy .NET-based Lambda applications. See here for more info.
- GitHub: the git repository that we are going to use for our source code. You can use what you prefer, like Bitbucket.
- Visual Studio Code: the cross-platform editor to write our .NET AWS Lambda application.
So, now let’s start and see what happens.
Create the .NET Lambda serverless project
The .NET Core CLI is the easiest way to create a .NET Lambda project. As always, you need to use the predefined AWS Lambda .NET Project templates with the dotnet new command. First, if you need to install the templates, open your command line tool, or terminal on macOS, and use the dotnet new -i command to install the Lambda Project Templates:
dotnet new -i Amazon.Lambda.Templates
after the installation was completed, you can proceed with creating the project. So, in your command line program, go to the base directory of your repository and use the serverless.AspNetCoreMinimalAPI as shown here:
dotnet new serverless.AspNetCoreMinimalAPI -n myAwesomeLambda
the project is now ready. Under the folder src/myAwesomeLambda, in the Program.cs, you’ll find all the useful code to run your Minimal API. You can change the code and implement the APIs based on your needs.
Setup your project for AWS CodePipeline
For this post, it is useful to look at these two specific files created by the serverless template:
aws-lambda-tools-defaults.jsonserverless.template
the aws-lambda-tools-defaults.json contains all the deployment info that you can use in the command line to deploy the lambda function. We’ll see the command line instruction later. The serverless.template, instead, is the JSON template that allows the creation of the serverless service by using AWS CloudFormation. you can find more info here. In this article we are going to use only the AWS Lambda Tools for .NET Core.
As seen in the previous post, we need to use the buildspec.yml file to build our solution by using AWS CodePipeline. Before we can proceed with the build and deploy command, we need to be sure that all the CLI are correctly installed on the build machine. To do that, we first need to install the latest dotnet version and then install, or update, the Amazon.Lambda.Tools by using the dotnet tool update command, as you can see in the following file buildspec.yml file:
version: 0.2
phases:
install:
commands:
- /usr/local/bin/dotnet-install.sh --channel LTS
- dotnet tool update -g Amazon.Lambda.Tools
build:
commands:
- dotnet lambda deploy-function myAwesomeLambda --project-location ./src/myAwesomeLambda/ --function-role myAwesomeLambdaRole --config-file aws-lambda-tools-defaults.json
The dotnet lambda deploy-function is the command you can call to build, package, and deploy your AWS Lambda function written in .NET. As written above, all the options specified here can be set also in the aws-lambda-tools-defaults-json file.
Here is an example:
{
"profile": "default",
"region": "eu-west-1",
"configuration": "Release",
"function-runtime": "dotnet6",
"function-memory-size": 256,
"function-timeout": 30,
"function-handler": "myAwesomeLambda",
"s3-prefix": "myAwesomeLambda/"
}
Now we can push our first repository version and then start configuring our AWS CodePipeline.
Configuring and building the AWS CodePipeline
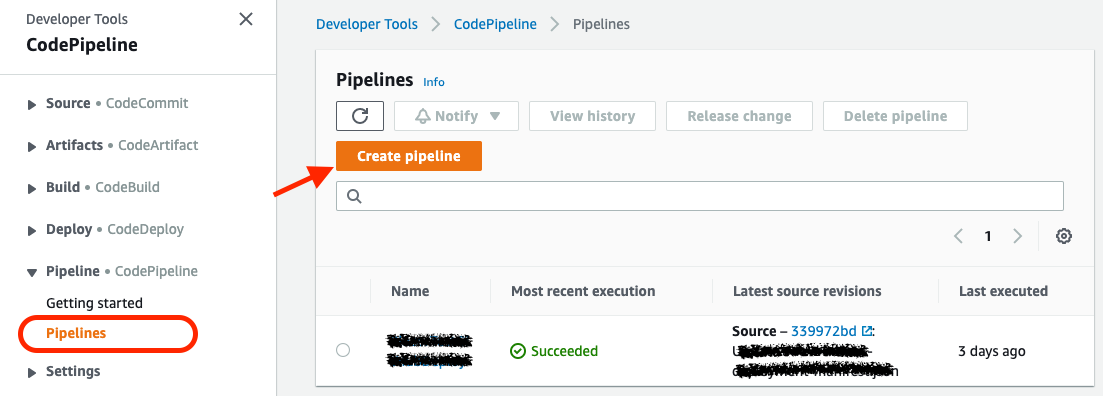
In a very similar way to what we have done in the previous post, we are going to create our AWS CodePipeline to build and publish the .NET AWS Lambda function. The AWS CodePipeline will pull the source code from GitHub and then pass the artifact to the build server.
So, first of all, we need to go to CodePipeline section on our AWS Console, and click the Create Pipeline button:
Define the Pipeline name and click on Next:
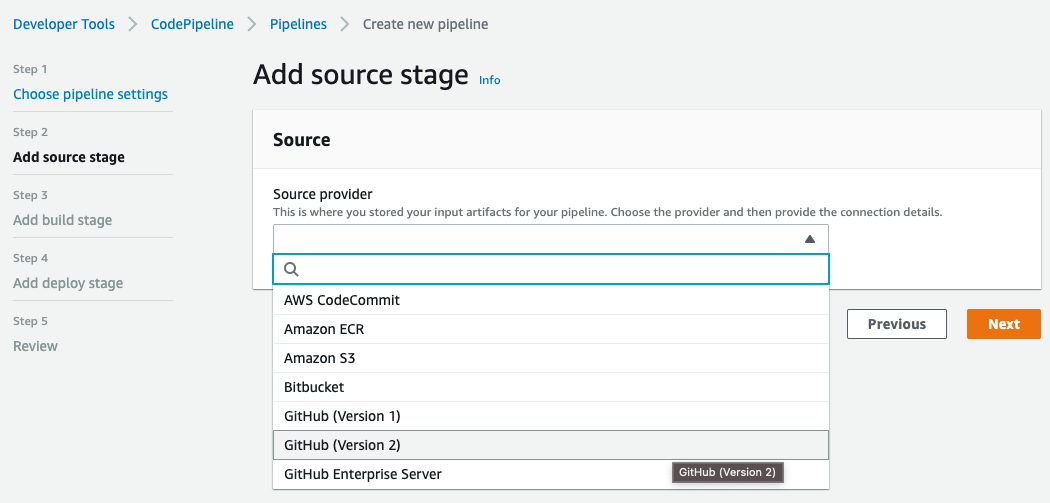
Select GitHub (Version 2) as Source provider. Then create a new GitHub connection by clicking on Connect to GitHub button:
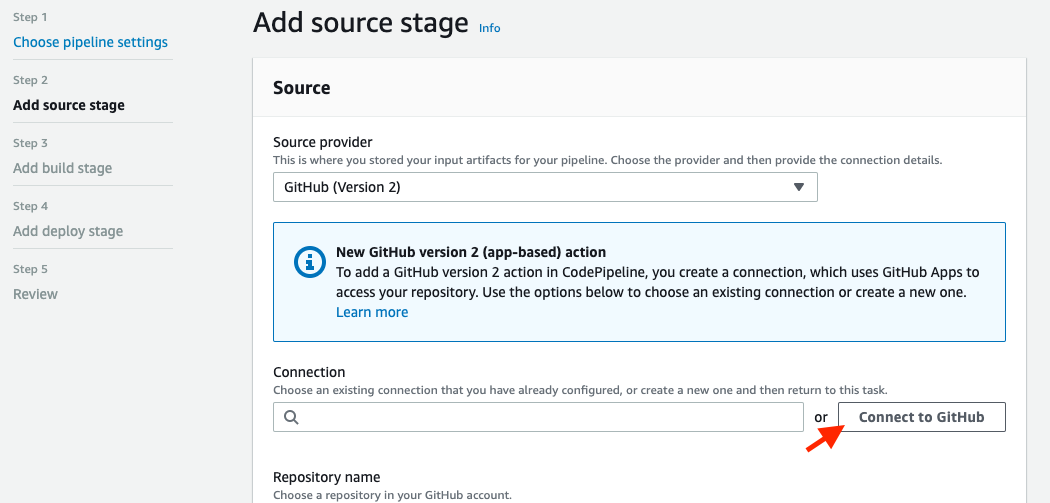
To use GitHub as a source, we first need to connect to our account. So on this page, set a name for the new connection and click Connect to GitHub:
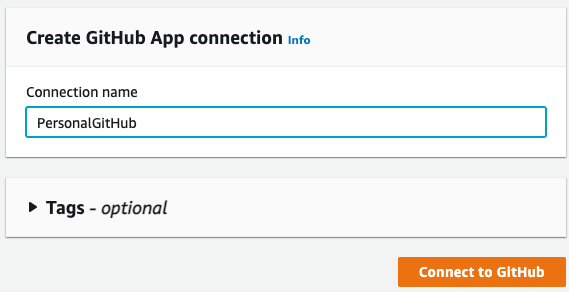
Click Install a new app to install AWS Connector for GitHub on your GitHub account and follow the instructions on the page. Then click Connect to complete this step:
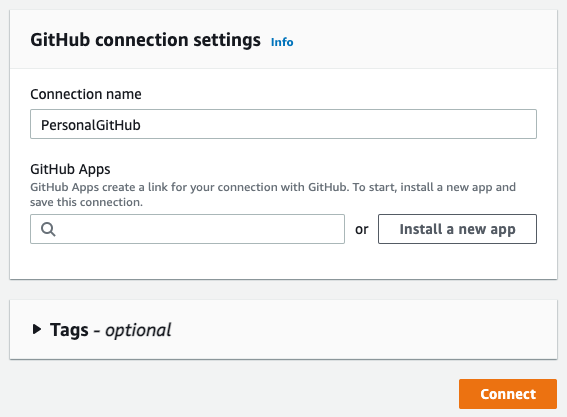
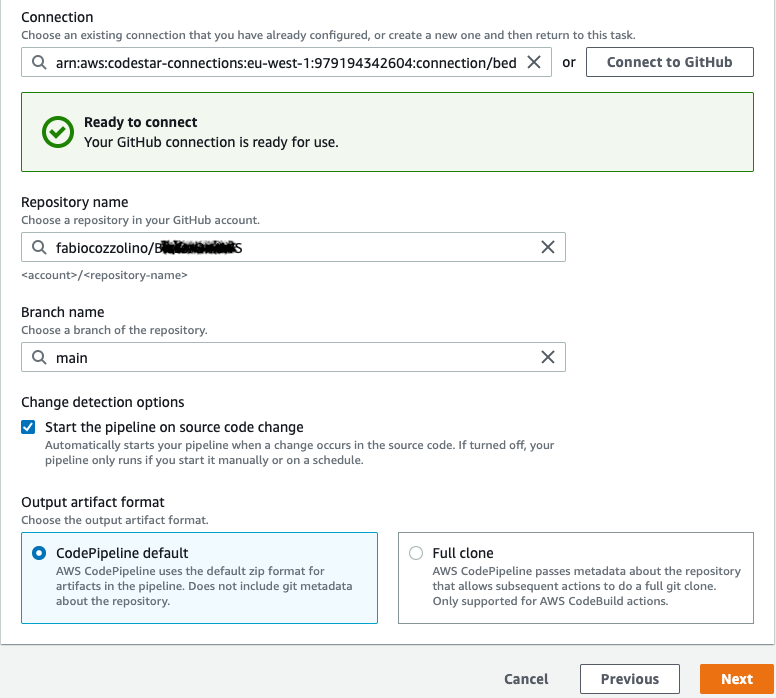
Now you can complete the GitHub source configuration by selecting the Repository and the Branch name and clicking to Next:
Setting up the build stage
After defining the source code repository, we need to create the build stage. In our project, we select AWS CodeBuild as the engine for the build. Specify your preferred region and create a new build project by clicking Create project:
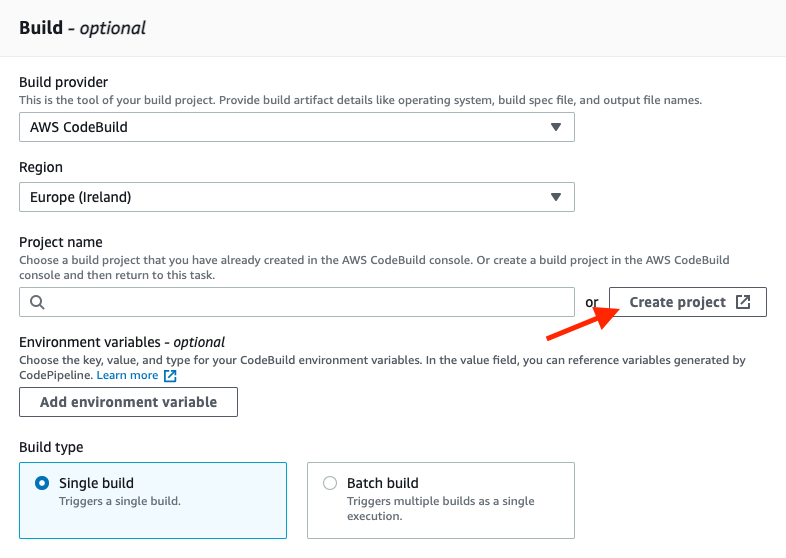
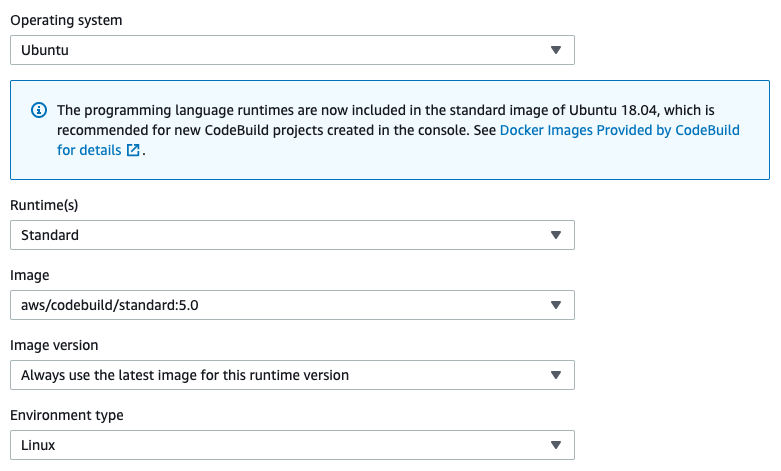
Here, after setting the Project name, go to the Environment section and choose Ubuntu as the operating system, as you can see in the image below:
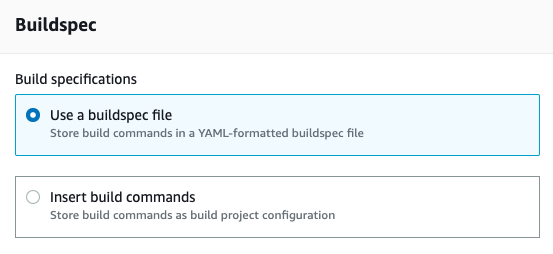
Make sure that the Use a buildspec file option is already selected in the Buildspec section. As above specified, we are going to use the buildspec.yml:
Define the Deploy stage
Since the deployment is made by the build server, we don’t need to set the Deploy stage, so we can skip this step.
Run the pipeline
We are ready. Now we can push our code to the remote repository and start the pipeline. At this time, you could encounter this error message:
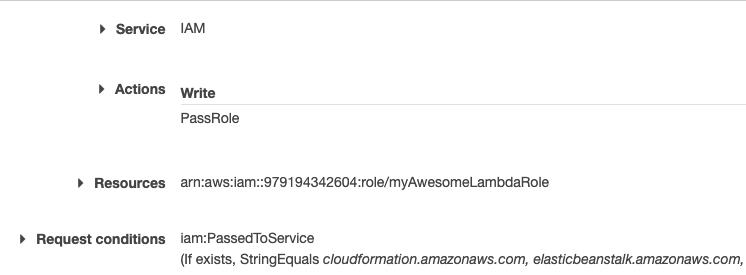
Error creating Lambda function: User: arn:aws:sts::assumed-role/build-role/AWSCodeBuild-xxx is not authorized to perform: iam:PassRole on resource: arn:aws:iam::xxx:role/myAwesomeLambdaRole because no identity-based policy allows the iam:PassRole action
To solve the issue, we need to assign the iam:PassRole permission to the running role of codebuild. So, go to IAM > Roles, select the role created for the AWS CodeBuild service, then create a specific policy by clicking on Add permission > Create inline policy:
and then select the rules as in the following image (be sure to have the target Lambda service role ARN):
After a few minutes, you can go to the AWS Lambda console section and test your running code.
Test your Lambda function
Now all the things are ready. Based on our configuration, the pipeline runs after each change in the GitHub source repository. In the end, you can go to the Lambda section, select your Lambda function instance and check if it is running fine.
In AWS console, you can also test your Lambda function. Simply click on Test tab and select your preferred template from the list:
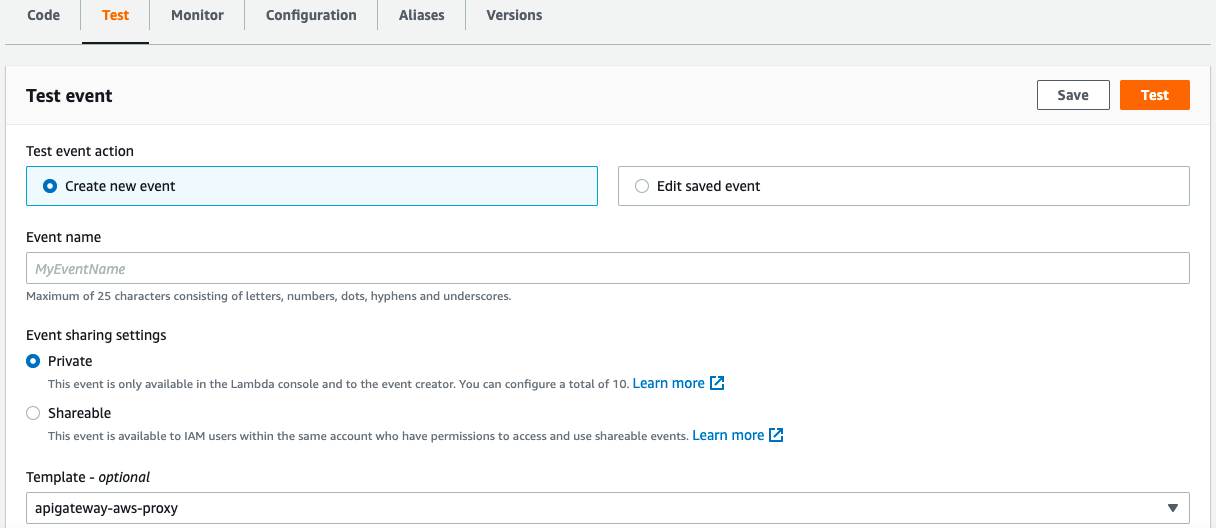
The simpler way to test the Lambda function is by using the API Gateway AWS Proxy template. Our Lambda function is built to reply to HTTP requests. An HTTP request can be made internally in your private network or could come from an external client, through an API Gateway. We’ll see this alternative way in the next post.
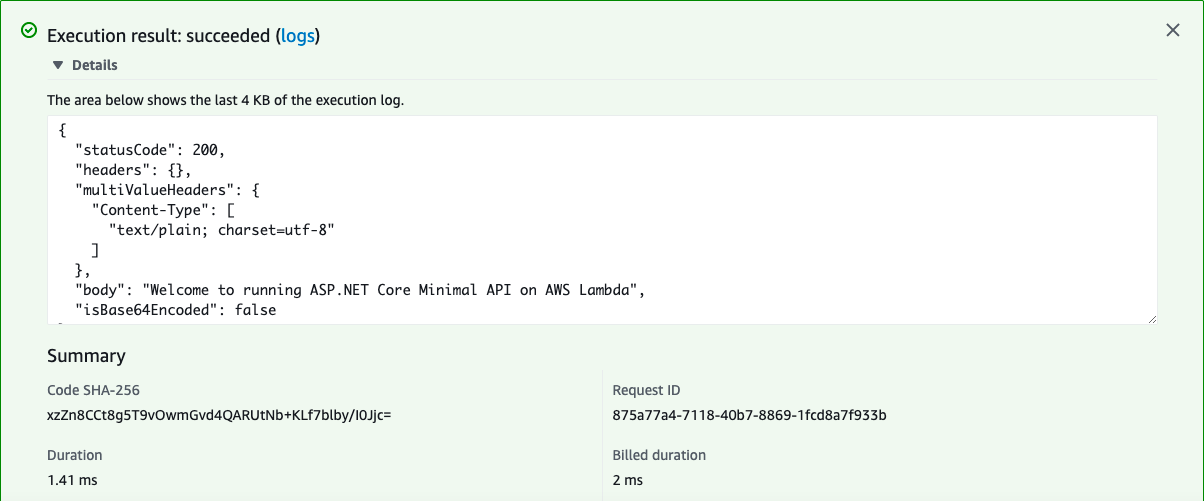
For the sake of this post, to test the call, we can use the following JSON document and set all the attributes useful to execute the request by invoking the HTTP GET method:
{
"body": "",
"resource": "/{proxy+}",
"path": "/",
"httpMethod": "GET"
}
Now you can push the Test button on upper right corner and see the result:
As always, any feedback is welcome!
Enjoy!




